

Data preprocessing key steps
Data preprocessing is a technique that is used to transform raw data into an understandable format. Raw data often contains numerous errors (lacking attribute values or certain attributes or only containing aggregate data) and lacks consistency (containing discrepancies in the code) and completeness. This is where data preprocessing comes into the picture and provides a proven method of resolving such issues.
Steps involved in Data Preprocessing in Machine Learning
- Importing necessary libraries.
- Importing the data-set.
- Checking and handling the missing values.
- Encoding Categorical Data.
- Feature Scaling.
Importing necessary libraries
Python has a list of amazing libraries and modules which help us in the data preprocessing process. Therefore in order to implement data preprocessing the first and foremost step is to import the necessary/required libraries. The libraries that we will be using in this tutorial are: NumPy NumPy is a Python library that allows you to perform numerical calculations. Think about linear algebra in school (or university) – NumPy is the Python library for it. It’s about matrices and vectors – and doing operations on top of them. At the heart of NumPy is a basic data type, called NumPy array. The NumPy API can be referenced here.
Pandas The Pandas library is the fundamental high-level building block for performing practical and real-world data analysis in Python. The Pandas library will not only allow us to import the data sets but also create the matrix of features and the dependent variable vector. The panda API can be referenced here.
Matplotlib The Matplotlib library allows us to plot some awesome charts which is a major requirement in Machine Learning.
import numpy as np import pandas as pd import matplotlib.pyplot as plt
Importing The Dataset and exploring the data
Once we have successfully imported all the required libraries, we then need to import the required dataset. For this purpose, we will be using the pandas library.
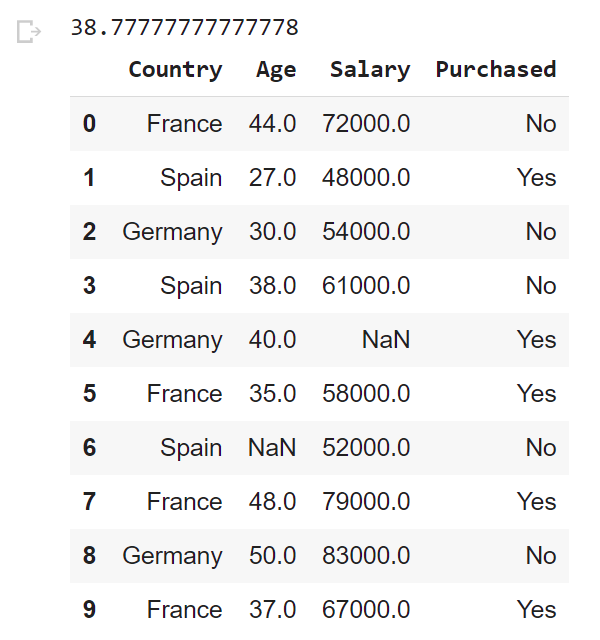
Let’s read the data (using read_csv), and take a look at the first 5 lines using the head method:
from google.colab import files
uploaded = files.upload()
dataset = pd.read_csv('data.csv')
dataset.head()
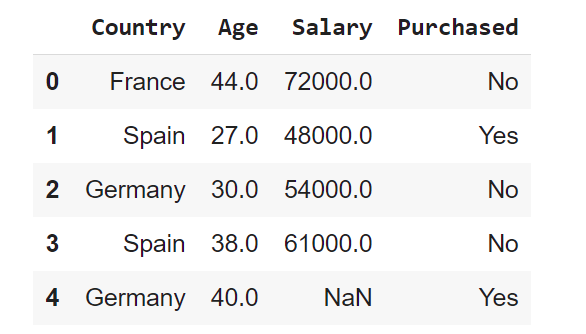
Let’s have a look at data dimensionality, feature names, and feature types.
print(dataset.shape)
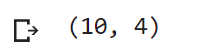
From the output, we can see that the table contains 10 rows and 4 columns.
Now let’s try printing out column names using columns:
print(dataset.columns)

We can use the info() method to output some general information about the dataframe:
print(dataset.info())
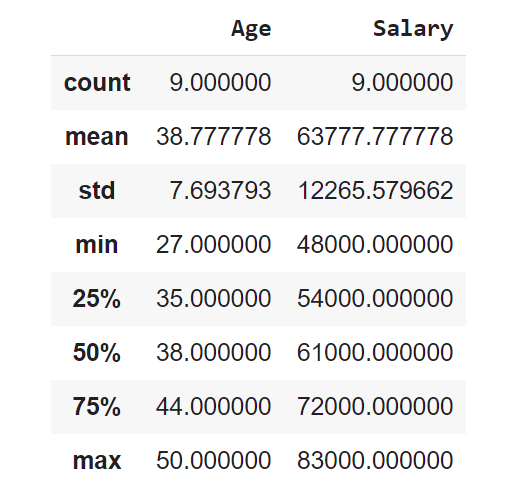
The describe method shows basic statistical characteristics of each numerical feature (int64 and float64 types): number of non-missing values, mean, standard deviation, range, median, 0.25 and 0.75 quartiles.
dataset.describe()
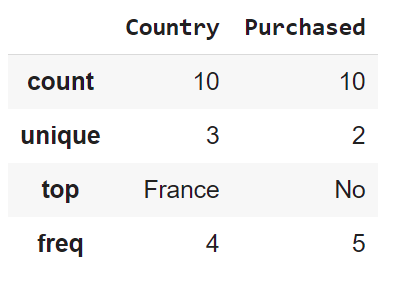
In order to see statistics on non-numerical features, one has to explicitly indicate data types of interest in the include parameter.
dataset.describe(include=['object', 'bool'])
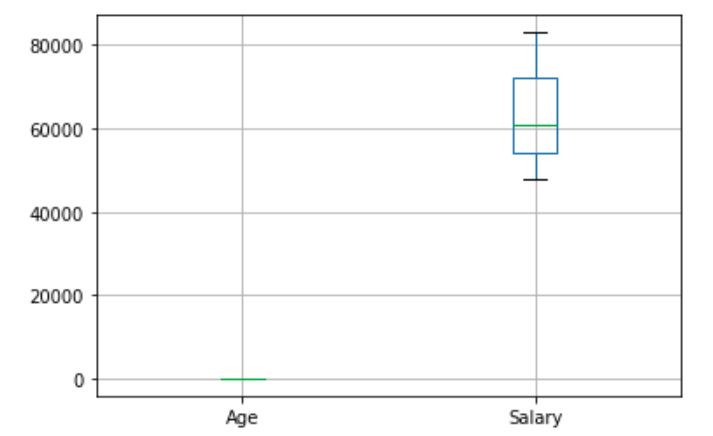
To get more statistic measures on numerical feature we can use the whisker plot. The box extends from the Q1 to Q3 quartile values of the data, with a line at the median (Q2). The whiskers extend from the edges of box to show the range of the data. By default, they extend no more than 1.5 * IQR (IQR = Q3 – Q1) from the edges of the box, ending at the farthest data point within that interval. Outliers are plotted as separate dots.
boxplot = dataset.boxplot()
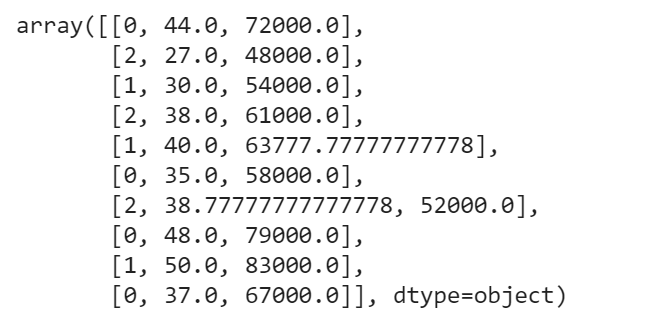
The matrix of features is used to describe the list of columns containing the independent variables to be processed and includes all lines in the given dataset. The target variable vector used to define the list of dependent variables in the existing dataset. iloc is an indexer for the Pandas Dataframe that is used to select rows and columns by their location/position/index.
x = dataset.iloc[:,:-1].values y = dataset.iloc[:,-1].values print(x) print(y)

Handling The Missing Values
While dealing with datasets, we often encounter missing values which might lead to incorrect deductions. Thus it is very important to handle missing values.
There are couple of ways in which we can handle the missing data.
Method 1: Delete The Particular Row Containing Null Value Drop the rows where at least one element is missing:
dataset.dropna(inplace=”true”)
This method is advised only when there are enough samples in the data set. One has to make sure that after we have deleted the data, there is no addition of bias. Removing the data will lead to loss of information which will not give the expected results while predicting the output.
Method 2 Method 2: Replacing The Missing Value With The Mean, Mode, or Median This strategy is best suited for features that have numeric data. We can simply calculate either of the mean, median, or mode of the feature and then replace the missing values with the calculated value. In our case, we will be calculating the mean to replace the missing values. Replacing the missing data with one of the above three approximations is also known as leaking the data while training.
➥ To deal with the missing values we need the help of the SimpleImputer class of the scikit-learn library.
Let’s check how many missing values do we have
dataset.isnull().sum()

Before replacing the missing values by the mean, let’s display the mean of ages
print(dataset['Age'].mean()) dataset
from sklearn.impute import SimpleImputer imputer = SimpleImputer(missing_values=np.nan, strategy='mean') imputer.fit(x[:, 1:3]) x[:, 1:3] = imputer.transform(x[:, 1:3]) print(x)

Encoding Categorical Data
Since, most of the machine learning models are based on Mathematical equations and you can intuitively understand that it would cause some problem if we can keep the Categorical data in the equations because we would only want numbers in the equations. So, we need to encode the Categorical Variable.
Like in our data set Country column will cause problem, so will convert into numerical values. To convert Categorical variable into Numerical data we can use *LabelEncoder() *class from preprocessing library.
from sklearn.preprocessing import LabelEncoder,OneHotEncoder le_X = LabelEncoder() x[:,0] = le_X.fit_transform(x[:,0])
One-Hot Encoding One hot encoding takes a column that has categorical data and then splits the column into multiple columns. Depending on which column has what value, they are replaced by 1s and 0s.
In our example, we will get three new columns, one for each country — India, Germany, and Japan. For rows with the first column value as Germany, the ‘Germany’ column will be split into three columns such that, the first column will have ‘1’ and the other two columns will have ‘0’s. Similarly, for rows that have the first column value as India, the second column will have ‘1’ and the other two columns will have ‘0’s. And for rows that have the first column value as Japan, the third column will have ‘1’ and the other two columns will have ‘0’s.
➥ To implement One-Hot Encoding we need the help of the OneHotEncoder class of the scikit-learn libraries’ preprocessing module and the ColumnTransformer class of the compose module.
from sklearn.compose import ColumnTransformer
ct = ColumnTransformer([('encoder', OneHotEncoder(),[0])], remainder="passthrough") # The last arg ([0]) is the list of columns you want to transform in this step
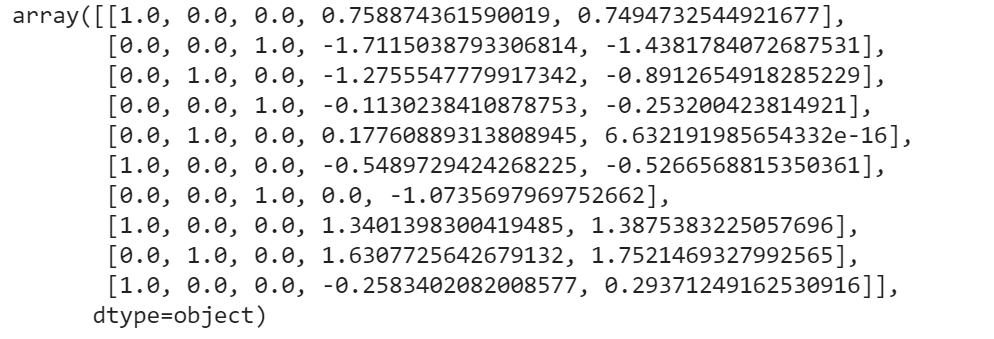
x =np.array(ct.fit_transform(x))
x

Feature Scaling
Feature scaling is the method to limit the range of variables so that they can be compared on common grounds. See the Age and Salary column. You can easily noticed Salary and Age variable don’t have the same scale and this will cause some issue in your machine learning model.
Let’s say we take two values from Age and Salary column Age- 40 and 27 Salary- 72000 and 48000
One can easily compute and see that age column will be dominated. So, there are several ways of scaling your data.
Since machine learning models rely on numbers to solve relations it is important to have similarly scaled data in a dataset. Scaling ensures that all data in a dataset falls in the same range.Unscaled data can cause inaccurate or false predictions.Some machine learning algorithms can handle feature scaling on its own and doesn’t require it explicitly.
As an example we give the code of the 3rd scalling method. We need to import the StandardScaler class of the scikit-learn library. Then we create the object of StandardScaler class. After that, we fit and transform the dataset
from sklearn.preprocessing import StandardScaler sc = StandardScaler() x[:, 3:] = sc.fit_transform(x[:, 3:]) x
Thanks for reading. If you like this, have a look at my other Data Science articles.